










观测云故障中心:帮助团队有效管理故障,减少故障恢复时间

真实场景:当紧急故障来袭
监控器突然告警:"支付服务不可用"。你猛地坐起来,打开手机——群里已经炸了,但没人知道谁负责处理。你一边翻聊天记录,一边开电脑查监控,还要同步问DBA、开发 等终于定位问题时,已经过去了40分钟。这是运维同学的日常。
几个核心概念
故障(Incident)
- 在观测云里,故障(Incident)由监控器触发,例如"支付服务不可用"。
- 关键特点:故障是对业务可用的威胁,必须有专人立即响应处理。
什么是值班(On-Call)?
系统 7×24 小时运行,但人不能 24 小时盯着屏幕。On-Call 就是一种轮班值守机制,确保任何时间点都有明确的人负责响应问题。
什么是升级?
现实场景:值班(On-Call)的手机静音了,没听见告警,后续也没人解决问题,故障越来越严重。
升级就是解决这个问题的兜底机制:规定时间内无人响应,自动并且持续扩大通知范围直到问题被解决。
关键原则:升级是确保关键故障必有响应和解决。
核心问题:为什么需要故障中心?
故障中心解决的是流程问题:谁来处理?处理到哪一步了?有没有升级机制?
场景一:告警无人响应
监控器触发 P0 告警"支付服务不可用",短信发给了一个"技术值班"群时无人响应。然后就是客服热线被打爆,老板才知道出了故障。
传统方式:告警发出后,没有明确的负责人和跟进机制。
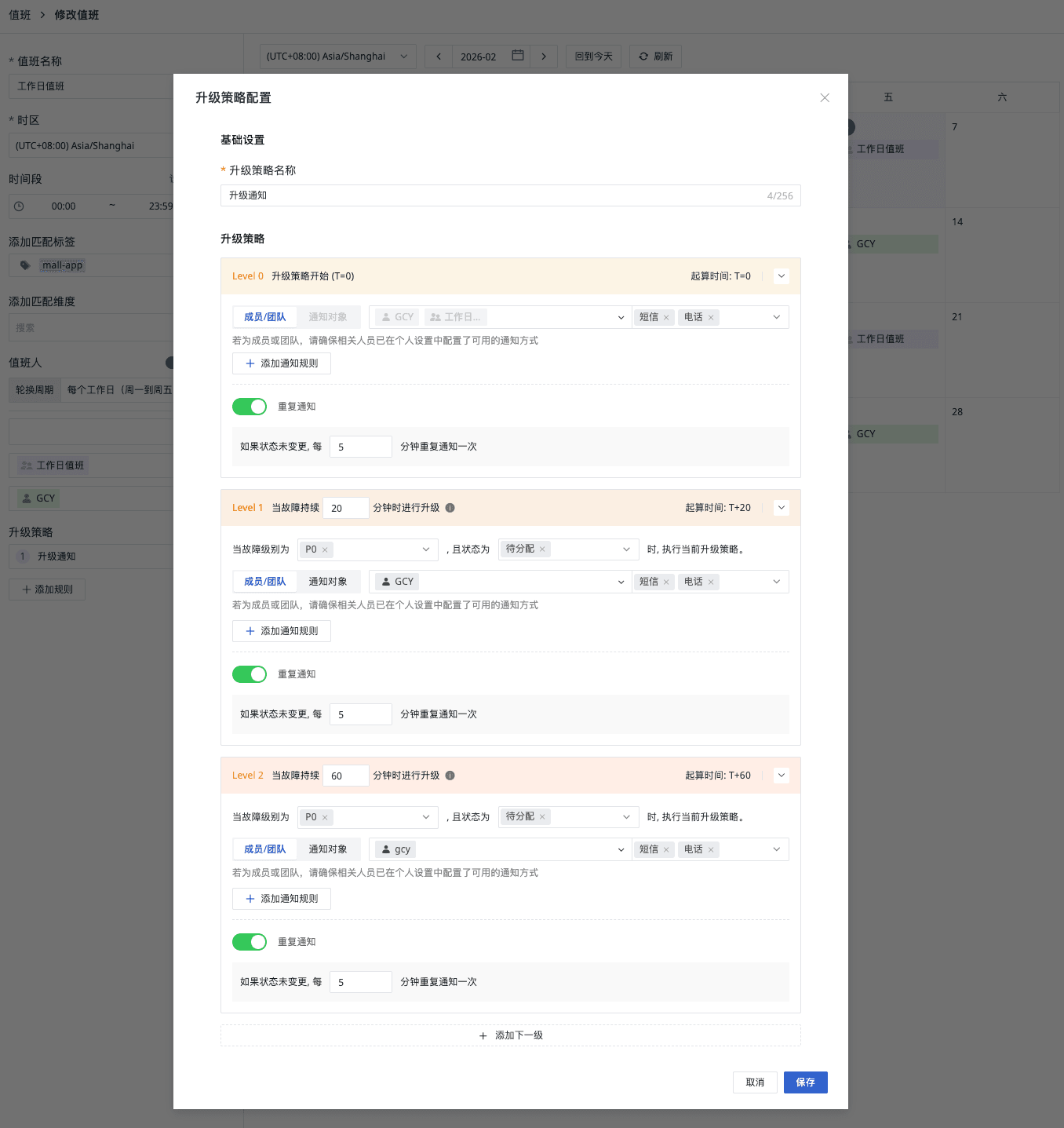
观测云故障中心:通过值班(On-Call)明确责任人,通过升级策略确保无人响应时自动扩大通知范围。如果故障在规定时间内未被认领,系统按预设规则升级通知。例如:
- T+0 分钟:不断通知值班人员,直至问题被解决
- T+20 分钟:如果状态仍为待分配(Open),不断通知团队负责人解决问题(也支持同时通知值班人员)
- T+60 分钟:不断通知部门经理解决问题
确保关键故障不遗漏、不悬置、有结果。
场景二:处理过程混乱
在紧急故障处理过程中时常出现没人知道当前谁在主导处理,处理到哪一步,历史操作记录在哪里,需要不断在群里跟进。
传统方式:故障响应依赖群聊同步,信息碎片化;
观测云故障中心:
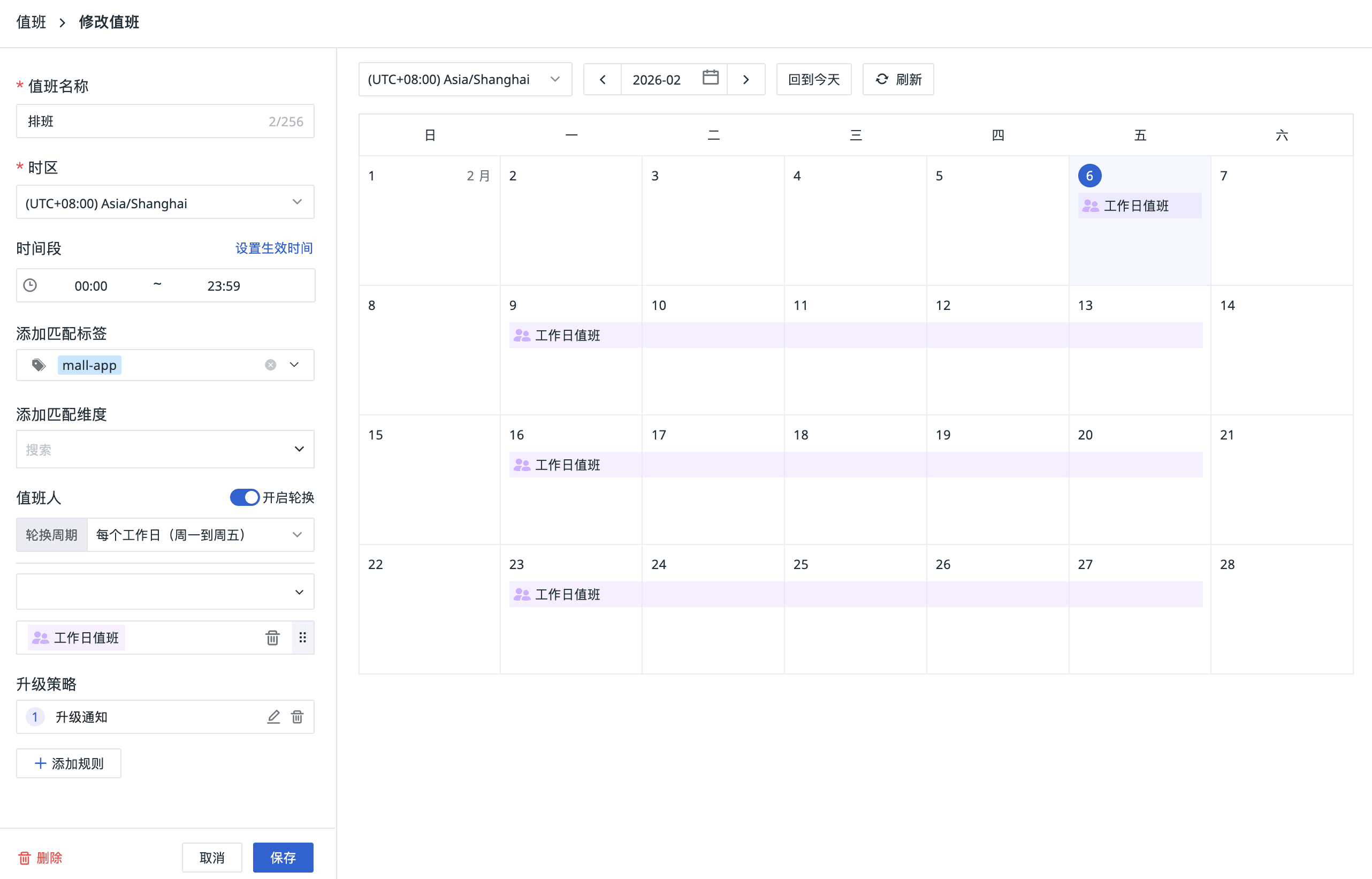
- 状态管理:待分配(Open) → 处理中(Working) → 已解决(Resolved) → 已关闭(Closed),每一步清晰可追溯
- 唯一负责人:只有当前负责人能变更状态,避免多人重复处理或互相推诿
- 操作记录:每个动作、每次通知、每次交接都有据可查
支持多团队轮换(工作日 A/B 团队,周末 C/D 团队)、标签匹配(DB 故障找 DBA)、时区设置(跨国团队协作),让值班体系真正落地。
场景三:数据孤岛
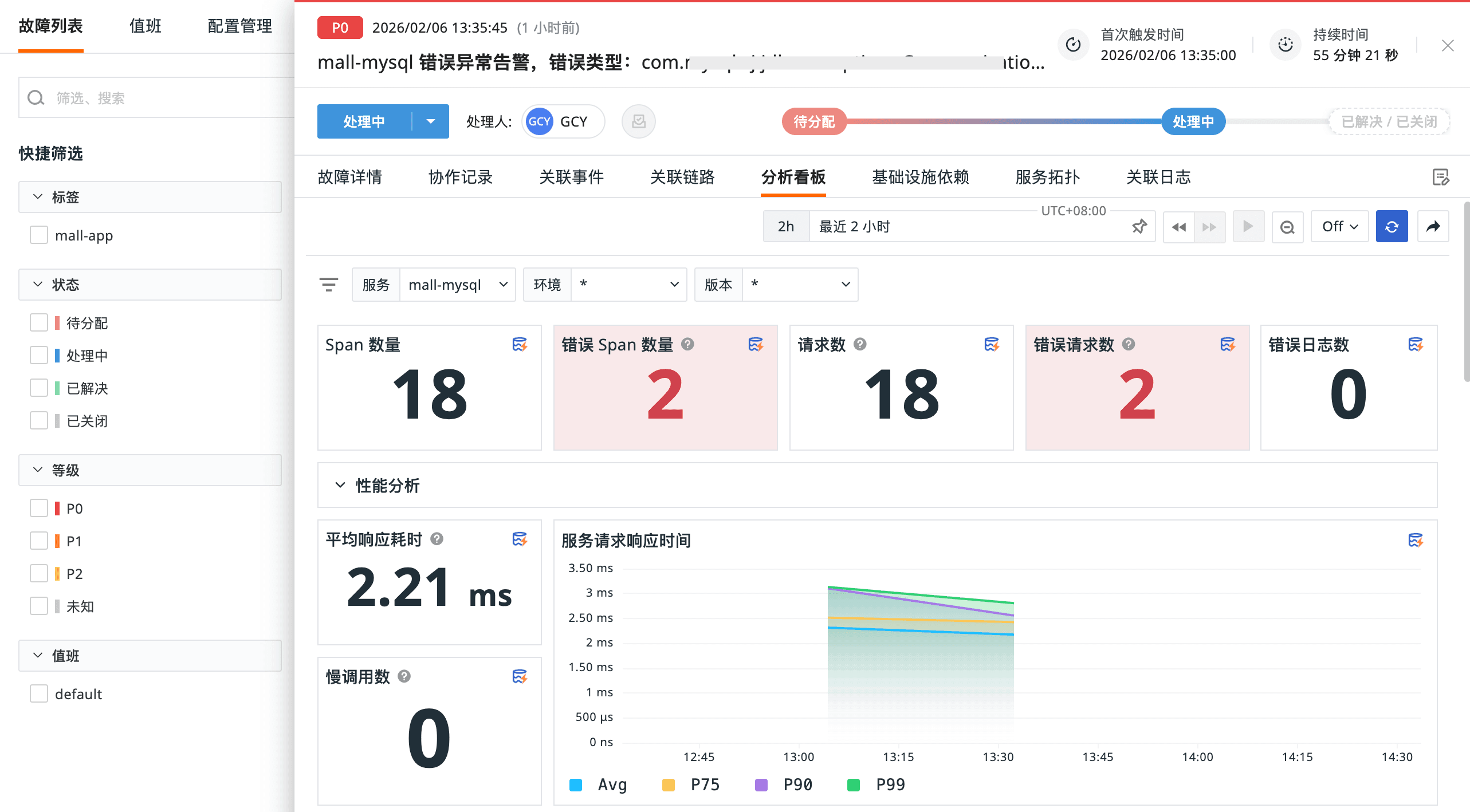
确认故障后,需要同时打开监控面板看指标趋势,日志查询看错误日志,链路追踪看调用链,基础设施看主机状态。在 4 个 Tab 来回切换以拼凑故障全貌。
故障中心自动关联所有故障(Incident)有关上下文,状态一页看完,大幅减少 MTTR。
实际使用场景
假设监控器检测到"支付服务不可用",自动创建 P0 故障:
- 值班通知:立即电话 + 短信通知当前值班人 A
- 认领响应:A在故障中心点击"认领此故障(Incident)",状态变为 Working,A 成为唯一负责人
- 查看上下文:故障(Incident)详情页自动展示最近 2 小时的关联数据
- 协调处理:A 发现是数据库问题,@DBA 团队在协作记录中沟通
- 状态流转:服务恢复后,A 标记 Resolved,观察稳定后关闭(Closed)
如果 A 在 15 分钟以内未认领故障(Incident),系统自动升级到团队负责人 B;30 分钟仍未处理,升级到技术总监 C。每个状态变更,通知发送,负责人交接都有记录。

人性化设计
值班人员可在个人状态标记"休假中",系统将自动跳过,通知下一位值班人。避免"人在沙滩躺着还被告警吵醒"的情况。
同时对于排班管理员来说,也可以避免因为有人临时休假而需要频繁修改排班。
总结:故障中心给SRE和运维带来什么?
| 痛点 | 传统方式 | 观测云故障中心 |
|---|---|---|
| 告警无人响应 | 群聊@所有人,靠运气 | On-Call明确责任人,升级策略兜底 |
| 处理过程混乱 | 群聊同步,信息碎片化 | 状态管理+唯一负责人,流程清晰 |
| 数据分散排查慢 | 多Tab切换,手动关联 | 上下文自动聚合,一页看完 |
| 复盘无据可查 | 靠记忆和聊天记录 | 完整时间线,MTTR量化 |
观测云故障中心是一套让故障"必有响应、必有流程、必有结果"的SRE工作流。
减少 MTTR,降低业务损失,让运维同学睡个好觉。
观测云故障中心,现已上线!


