













热线电话:400-882-3320

待分配 frontend-proxy 5xx 与 SLO 异常 持续 32m
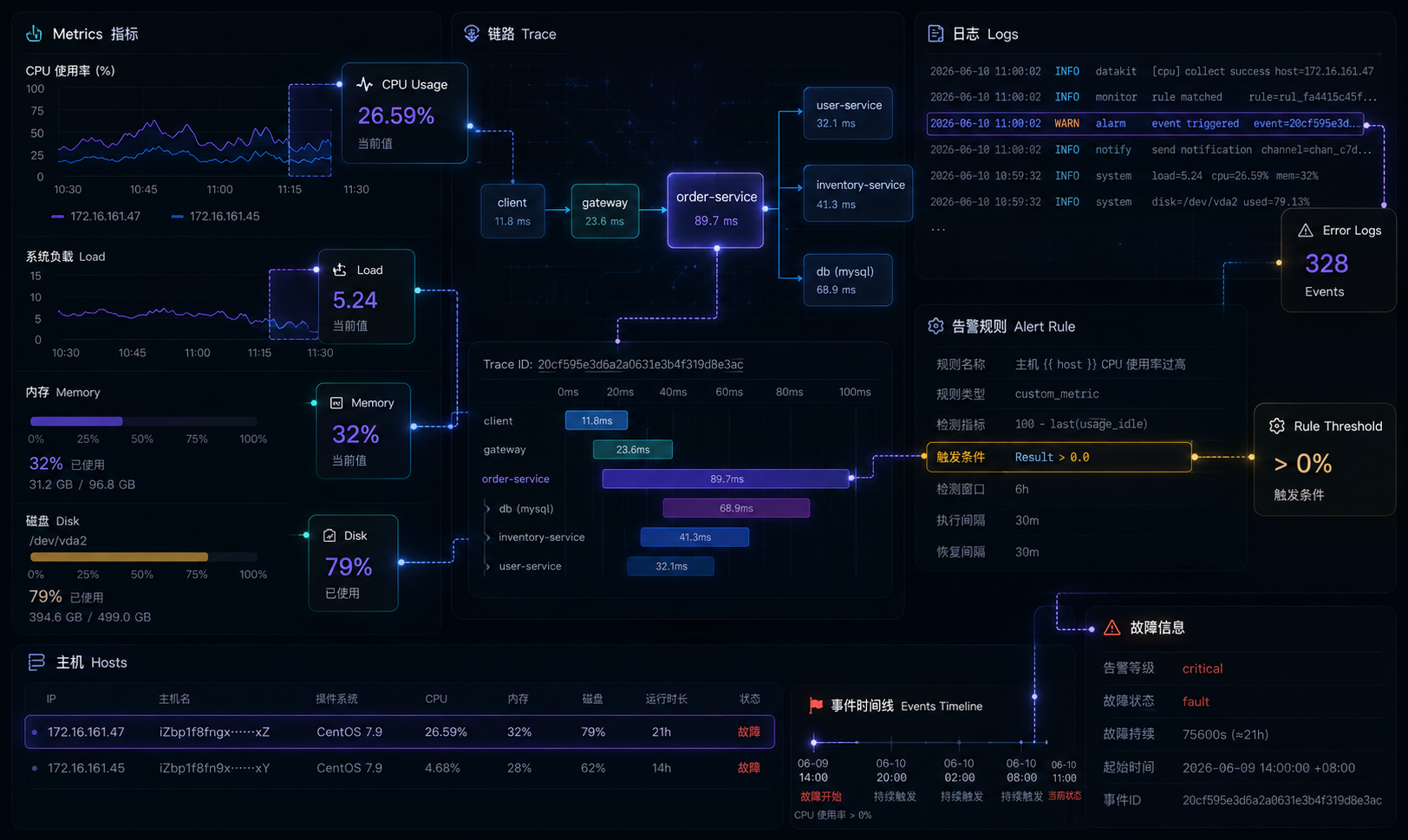
入口服务 5xx 突增,SLO 与 Trace 同窗口告警,等待接管。
值班SRE 值班群 最新操作触发新故障 处理人未分配
入口服务 5xx 突增,SLO 与 Trace 同窗口告警,等待接管。
Pod 重启 12 次,最近一次退出码 1,日志指向 Redis 连接配置异常。
P95 延迟高于基线 2.8 倍,尚未触发 SLO 严重告警。
当前故障已带入 service、resource、namespace、timeRange 和事件 ID。
变更状态表示您将负责处理此故障。Agent 将把证据、审批和验证结果写入操作记录。
根据团队角色和业务场景,快速创建专属 Agent。配置知识、工具和权限,让 Agent 更懂你的业务。
 运维专家
运维专家 性能分析师
性能分析师 SRE 助手
SRE 助手安全连接到你的生产环境,提供系统监控和工具,执行排查、分析、变更等真实任务,闭环解决问题。

深度集成观测云,访问指标、日志、链路等数据,引导你进一步分析根因,提供可行建议。
无缝集成 Slack、飞书、钉钉、企业微信等平台,在你熟悉的环境中与 Agent 协作。
与 Coding Agent 深度协作,自动分析问题,定位代码,生成修复方案,加速线上问题闭环。
通过自动化规则和任务调度,Agent 可持续监控、自动处理、生成报告,保障系统稳定运行。