













热线电话:400-882-3320
微信扫码
加入官方交流群
APM / Application Performance Monitoring
当接口变慢、错误率升高或微服务依赖难以排查时,观测云应用性能监控(APM 平台)通过 Trace、服务拓扑、接口耗时、错误、Profiling 和日志关联,把一次请求从用户入口追到服务、代码和资源瓶颈。
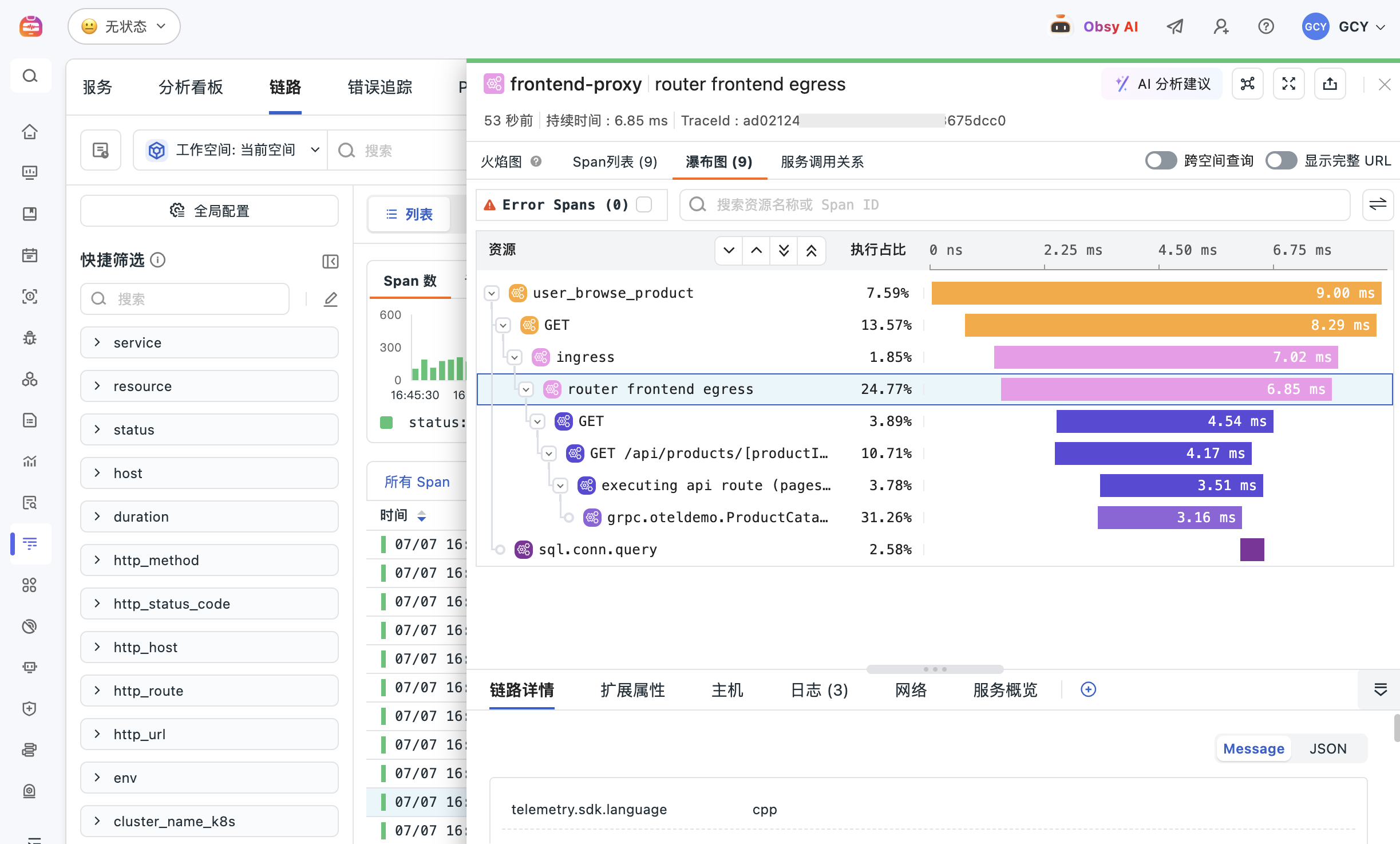

接入观测云后,我们打通了端到端的交易链路:从网络和服务器资源、应用服务、到前端页面和 POS 终端,实现全链路性能实时监控。在一次告警中,我们能立即看到是哪一段出现了性能瓶颈、用户体验下降或日志异常,帮助团队多维度定位问题,将性能优化落地。
APM 解决什么问题
应用性能监控面向研发、SRE 和运维团队,持续采集应用调用链、接口耗时、错误、吞吐量、依赖关系和代码热点。观测云 APM 平台把这些数据与日志关联、基础设施指标、用户访问体验放在同一上下文中,让团队不用在多个工具之间切换,就能判断影响范围、定位根因并验证修复效果。
真实排障路径
APM 的价值不只是展示 Trace。它先识别真正影响业务的慢与错,再沿调用链、日志和 Profiling 把根因落到具体服务、依赖或代码热点。

查看证据响应时间、错误状态、服务与接口调用路径
得到结论确认最慢 Span 和异常发生位置
查看证据错误日志、主机指标、容器状态与告警事件
得到结论区分应用错误、资源不足与外部依赖异常
查看证据CPU、内存、锁等待、函数调用与 SQL 耗时
得到结论形成可以直接执行和回读验证的优化点
语言探针 / OpenTelemetry → 服务、接口与 Trace → 日志、基础设施和 Profiling 上下文
适合微服务、分布式调用和关键交易链路的研发、SRE 与平台工程团队。
需要应用侧接入探针或 OpenTelemetry;前端真实体验可继续关联 RUM,资源瓶颈可继续关联基础设施监控。
常见问题
继续探索
从产品文档、相关方案到技术实践,按当前问题选择下一步。
来自产品实践、故障排查与技术方案的精选内容









